Cache Optimizations
2026-02-07 21:48
Status: #child
Tags: #software #engineering
Cache Optimization
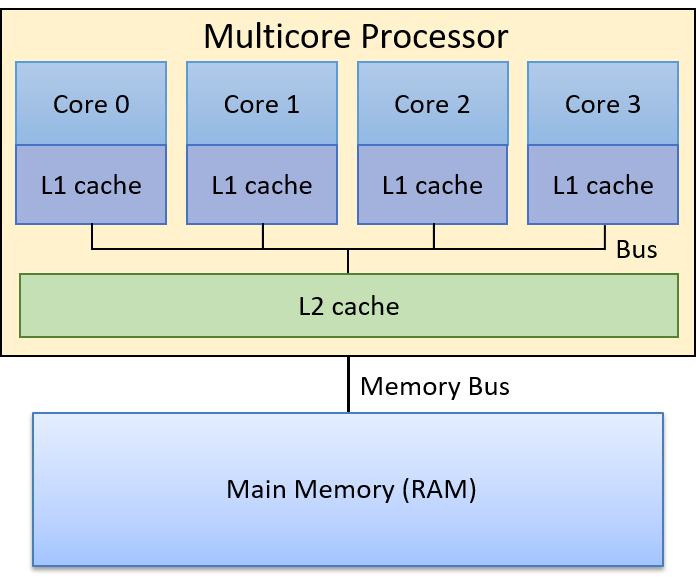
Examples of system caching:
- Processor caches
- Administered by the processor itself
- Moves DRAM to SRAM cache memory
- Buffer cache
- Administered by the kernel
- Moves from secondary storage devices to main DRAM memory
sdiocache- Administered at the application level
- Moves data from secondary storage to application buffer cache
- Browser cache
- Administered by the browser (application level)
- Brings remote websites over network to storage devices
Expense of storage
As we discussed in Memory Hierarchy, the battle is between financial feasibility and performance provided by storage devices.
Access cost framework
: Cost of accessing N units of data at once ( ) - Cost is often measured in terms of time (latency)
if it's impossible to access those units at once
- As an estimate, many access costs are approximated by
- R is the cost per request, independent of the number of units accessed by said request
- U is the cost per unit
System calls can be a really good example. One can consider the cost of a read(fd, buf, sz) system call.
Assuming that a read roughly obeys the rule stated above, will the cost per request be higher than the cost per unit or vice versa?
More than cost
Other metrics we have considered in Memory Hierarchy are the latency and throughput which are the inverse of each other for some storage technologies.
For example, on a true random access device, the cost framework involves a cost per request of ~0 which makes the cost of accessing N units just be NU.
For other technologies (like SSDs), latency and throughput can diverge!
- Assume per-request cost is much smaller than per-unit cost (R≪UR≪U)
- Example: main memory access
- Then
- Throughput per unit with N-unit requests = N/CN≈1
- Latency = C1≈U
- Assume per-unit cost is much smaller than per-request cost (U≪R)
- Examples: system calls, reading/writing a disk drive
- Then CN≈R
- Throughput per unit with N-unit requests = N/CN≈N/R
- Latency = C1≈R
- Assume per-unit and per-request costs are comparable (neither dominates)
- Example: network communication
- Then
depends on both R and U
Optimization strats
- Reducing number of requests
- Avoiding redundant requests
- Do the same work in fewer requests
- Batching (read and write)
- Prefetching (read)
- Write coalescing (write)
- See eMMCs
- Parallel access (read and write)
Batching
- Combine multiple requests into a single one
- Reading 1KB block at once instead of reading 1B 1000 times.
- Reduce the total per-request cost R
Prefetching
- Read data into cache before we need it
- Reduces the number of requests
- Often can involve some bit of context and complexity to do this
Write coalescing
- Delay writes to underlying storage unit until several writes to cache
- EXT4 Filesystem does some automatic coalescing when interacting with flash devices
- Although this kinda sucks on eMMC setup I have in mind...
Parallel or background access
- This would benefit from more hardware capabilities
- Can also involve some added abstractions in the application level