Cache Locality
2026-02-07 23:04
Status: #child
Tags: #software #engineering
Cache Locality
Locality is the common access pattern that is shared among most programs. Hardware designers tend to also build hardware that exploits good locality to automatically move data into the appropriate storage location.
Specifically, a system improves performance by moving a subset of data into a program is actively using into storage that is closer to the CPU computation circuitry.
Systems generally exploit two forms of locality:
- Temporal locality: Programs tend to access the same data repeatedly over time. That is, if a program has used a variable recently, it will prob need it again soon.
- Spatial locality: Programs tend to access data that is near each other. If a program accesses N and N+4, then it is likely to also look for N+8.
Let's consider the following example
int sum_array(int *array, int len) {
int i;
int sum = 0;
for (i = 0; i < len; i++) {
sum += array[i];
}
return sum;
}
Here we can see multiple variables that are used over many iterations in a row; utilizing temporal locality means that accessing these variables will be much faster on subsequent iterations of the loop.
We can also see spacial locality here since we look at the elements in the array in sequential order. The number of additional ints that we cache here depends on the cache's block size - the amount of data transferred into the cache at once.
A 16-byte block size system copies four integers from memory into the cache at a time as an example.
How can we architect software that utilizes good locality patterns you ask?
Consider the following odd program:
float averageMat_v2(int **mat, int n) {
int i, j, total = 0;
for (i = 0; i < n; i++) {
for (j = 0; j < n; j++) {
// Note indexing: [j][i]
total += mat[j][i];
}
}
return (float) total / (n * n);
}
Due to the row-major order organization of a matrix in memory, reading from the matrix by repeatedly jumping between rows will violate spacial locality and thus be much slower than the normal indexing alternative which says "start with ith row and read every column there".
From Locality to Caches
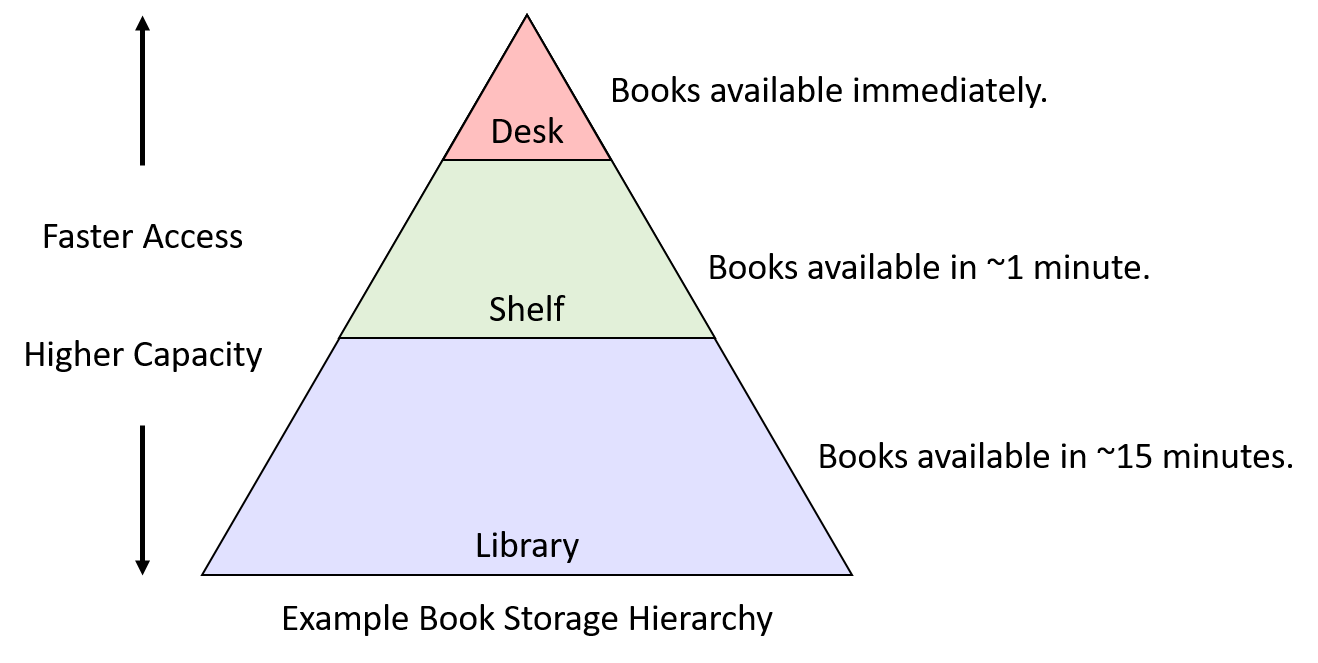
Suppose Avicenna has a small desk which can store only three books at a time. Outside his study room there is a bookshelf, which can store many more books! There is also a nearby palace library which he has access to; however, the palace is ~15 minutes away.
Temporal Locality
Avicenna will keep the books he is using frequently nearby on the desk. The occasionally used books will be outside his study room on the shelves. The books that he rarely reads will be in the palace. The algorithm that computers use utilizes the past as a way to learn access patterns which could be applied to Avicenna here too:
- When avicenna needs a book, he will get it from wherever it currently is and moves it to his desk.
- If the desk is full, he will move the book that was used least recently to the shelf.
- If the shelf is full, he will return the least recently used book on the shelf to the library to free some space.
Applying this strategy to primary storage devices looks remarkably similar to the book example: as data is loaded into CPU registers from main memory, make room for it in the CPU cache. If the cache is already full, make room in the cache by evicting the least recently used cache data to main memory
Spatial Locality
When making a trip to the palace, Avicenna should retrieve more than one book to reduce the likelihood of future trips to the palace (and thus the cost of 30 minutes of round trip time).
If Avicenna wants to read Albidaya walnihaya then it might make sense to get the full set or at least the first three books instead of the first one only since Avicenna is likely to fly through that and move to the next one pretty quickly :)